- Published on
Experiment Tracking and Versioning with WandB
- Authors

- Name
- Kenneth Lim
In the iterative process of tuning machine learning models, making tweaks and running experiments repeatedly is a standard practice. Without proper tools or systems in place, tracking these experiments and their results can become chaotic, leading to inefficiencies and potential loss of valuable insights. This is where experiment tracking and versioning become essential.
Experiment Tracking. Experiment tracking, as described by Huyen (2022), is akin to "babysitting the learning process" of a machine learning model. It involves monitoring and recording everything that happens during training—such as loss curves, evaluation metrics, and changes in parameters—to ensure that the model is actually learning as intended. By tracking these details, practitioners can detect early signs of issues like overfitting or vanishing gradients and evaluate the model's progress effectively. This meticulous tracking not only helps diagnose problems during training but also lays the foundation for meaningful comparisons and future improvements.
Versioning. Huyen (2022) mentions the process of logging all the details of an experiment for the purpose of possibly recreating it later or comparing it with other experiments is called versioning. This includes recording information such as datasets, code versions, hyperparameters, and model configurations, as well as the outputs or other artifacts. Versioning ensures that every experiment is traceable, making it possible to reproduce results or analyze differences across experiments systematically.
In this post, I'll be mainly using Weights And Biases: Experiments (WandB) as my experiment tracking platform. I’ll be training a LightGBM model on the UCI Wine Quality dataset with a simple grid search via Ray Tune to get the best-performing model. Along the way, you’ll see how WandB is used to track, log, and compare experiments bringing structure and clarity to this iterative process. Let’s get started! 🚀
1. Experiment Tracking Design
To ensure a robust and insightful machine learning workflow, I’ve identified a few commonly used key metrics and outputs to track. These elements will provide a detailed view of the model’s performance, data distribution, and learning behavior.
Data Distribution Analysis. It’s important to confirm that the training and validation datasets share the same distribution. This will be done by generating Empirical Cumulative Distribution Function (ECDF) plots for the target variable across these datasets. Additionally, an overview of the target variable distribution will be captured to ensure there are no anomalies or imbalances that could bias the model.
Model Learning Behavior. To monitor how the model learns during training, a validation curve of Mean Squared Error (MSE) against the number of boosting iterations will be plotted. This will provide insights into the rate of learning, helping to identify issues like underfitting or overfitting early in the training process.
Feature Importance and Relationships. Understanding the features driving the model’s predictions is vital for interpretability. I will capture the learned feature importance values from the LightGBM model to quantify the influence of each feature. Furthermore, using SHAP (SHapley Additive exPlanations), I’ll generate a summary plot to explore the relationships the model has learned with respect to the target variable. To dive deeper, SHAP partial dependence plots will visualize these relationships in greater detail.
Post-Modeling Analysis. DataFrames for feature importance values, summary statistics of the training and validation datasets, and inference data with associated errors will be logged. These will be instrumental in identifying areas for improvement, diagnosing issues, and refining the model.
By systematically capturing and logging these elements, the experiment tracking system will not only provide transparency and reproducibility but also enable in-depth analysis to optimize the model and improve future iterations. This design ensures that every step of the modeling process is well-documented and contributes to actionable insights.
Similar to any other software engineering projects, it’s also easy to over-engineer a tracking system. Begin by tracking only the most essential metrics and outputs, and expand as needed. Let's keep it simple.
2. Implementation
With the design in place, implementing the code though relatively straight-forward, still takes a while. Here's a few tips when using Ray Tune:
- When using Ray tune in local, ensure all running jobs have sufficient resources. e.g. running 10 models simultaneously each using all cores/threads is likely to result in deadlock.
- Calling
train.report({ done: True, ... })results in the Ray worker terminating the job. If you're using thedoneflag, make sure it runs after anywandb.log.
import lightgbm as lgb
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import ray
import seaborn as sns
import shap
import sklearn.datasets
import sklearn.metrics
import wandb
from lightgbm import LGBMRegressor
from pathlib import Path
from scipy import stats
from sklearn.model_selection import train_test_split
from ray import train, tune
from ray.tune.integration.lightgbm import TuneReportCheckpointCallback
from ucimlrepo import fetch_ucirepo
from wandb.integration.lightgbm import wandb_callback, log_summary
PROJECT_NAME = "LightGBM_Wandb_example"
def setup_wandb(config, **kwargs):
# wandb.login() # Provide API key here if needed
wandb.init(config=config, **kwargs)
def load_dataset():
wine_quality = fetch_ucirepo(id=186)
X = wine_quality.data.features
y = wine_quality.data.targets.quality
return X, y
def log_inference_data(ytrue, yhat):
table = wandb.Table(
dataframe=pd.DataFrame(
{
"y": ytrue,
"yhat": yhat,
"err": ytrue - yhat,
"abs_err": np.abs(ytrue - yhat),
}
).sort_values("abs_err", ascending=False)
)
wandb.log({"Inference Data": table})
def log_data_statistics(suffix, data):
table = wandb.Table(
dataframe=(
data.describe()
.transpose()
.reset_index()
.rename({"index": "feature"}, axis=1)
)
)
wandb.log({f"Dataset: {suffix}": table})
def log_ecdf(x1, x2, var_name):
ks_stat, p_value = stats.ks_2samp(x1, x2)
info = f"[K-S (stat: {ks_stat.round(4)}, p-val: {p_value.round(4)})]"
plt.figure(figsize=(4, 6))
ax = sns.ecdfplot(pd.DataFrame({f"{var_name}-1": x1, f"{var_name}-2": x2}))
ax.text(0.95, 0.05, info, transform=ax.transAxes, fontsize=10, ha="right")
plt.xlabel("Values")
plt.grid()
plt.tight_layout()
wandb.log({f"ECDF {var_name}": plt})
def log_dist(x, var_name, kind="hist"):
sns.displot(x, height=4, aspect=1.2, kind=kind)
plt.grid()
plt.tight_layout()
wandb.log({f"DistPlot {var_name}": plt})
def log_shap(model, X):
explainer = shap.Explainer(model, X)
shap_values = explainer(X, check_additivity=False)
shap.plots.beeswarm(shap_values, show=False)
wandb.log({f"SHAP Summary": wandb.Image(plt.gcf())})
for varname in ["free_sulfur_dioxide", "sulphates", "volatile_acidity"]:
shap.plots.scatter(shap_values[:, varname], show=False)
wandb.log({f"SHAP {varname}": wandb.Image(plt.gcf())})
def train_lightgbm(config):
setup_wandb(config, project=PROJECT_NAME)
try:
data, target = load_dataset()
train_x, valid_x, train_y, valid_y = train_test_split(
data, target, test_size=0.2
)
model = LGBMRegressor(**config)
model.fit(
train_x,
train_y,
eval_set=[(train_x, train_y), (valid_x, valid_y)],
eval_names=["train", "valid"],
eval_metric=["l2", "rmse"],
callbacks=[
# Early stopping if no improvement
lgb.early_stopping(stopping_rounds=100),
# Used by Ray Tune Schedulers and Search Algos
TuneReportCheckpointCallback({"mse": "valid-l2"}),
# Log learning curve on WandB
wandb_callback(),
],
)
# Log model as artifact
log_summary(model.booster_, save_model_checkpoint=True)
# Evaluate results
preds = model.predict(valid_x)
results = {
"mse": sklearn.metrics.mean_squared_error(valid_y, preds),
"rmse": sklearn.metrics.mean_squared_error(valid_y, preds) ** 0.5,
"r2_score": sklearn.metrics.r2_score(valid_y, preds),
}
# Update Summary metrics on WandB
for k, v in results.items():
wandb.summary[k] = v
# log training and inference data statistics
log_data_statistics("train_x", train_x)
log_data_statistics("valid_x", valid_x)
log_ecdf(train_x.free_sulfur_dioxide, valid_x.free_sulfur_dioxide, "y")
log_dist(train_y, "y")
log_dist(preds - valid_y.values, "Residuals", kind="kde")
log_inference_data(valid_y, preds)
log_shap(model, valid_x)
train.report(results) # Report results to Ray Tune
except Exception as e:
print("Something went wrong!")
raise Exception(e)
finally:
wandb.finish()
def run_ray_tune():
config = {
"objective": "regression",
"n_estimators": 2000,
"learning_rate": 1e-3,
"max_depth": 8,
"subsample": tune.grid_search([0.8, 0.9, 1.0]),
"colsample_bytree": 1.0,
"min_child_samples": 5,
"n_jobs": 1, # Make sure to lower n_threads to avoid deadlocks
}
tuner = tune.Tuner(
train_lightgbm,
tune_config=tune.TuneConfig(
metric="mse",
mode="min",
num_samples=1, # simulate # of samples per set of hyperparameter config
),
param_space=config,
)
results = tuner.fit()
print("Best hyperparameters found were: ", results.get_best_result().config)
if __name__ == "__main__":
run_ray_tune()
3. Viewing Results
WandB makes it really easily to track different versions of the models and compare their performances. Logging into WandB dashboard, visiting the "Workspace" tab in your WandB project, you can easily add, change the dashboard layouts, charts or data tables. I've made it to compare the model learning performances, and feature importances.
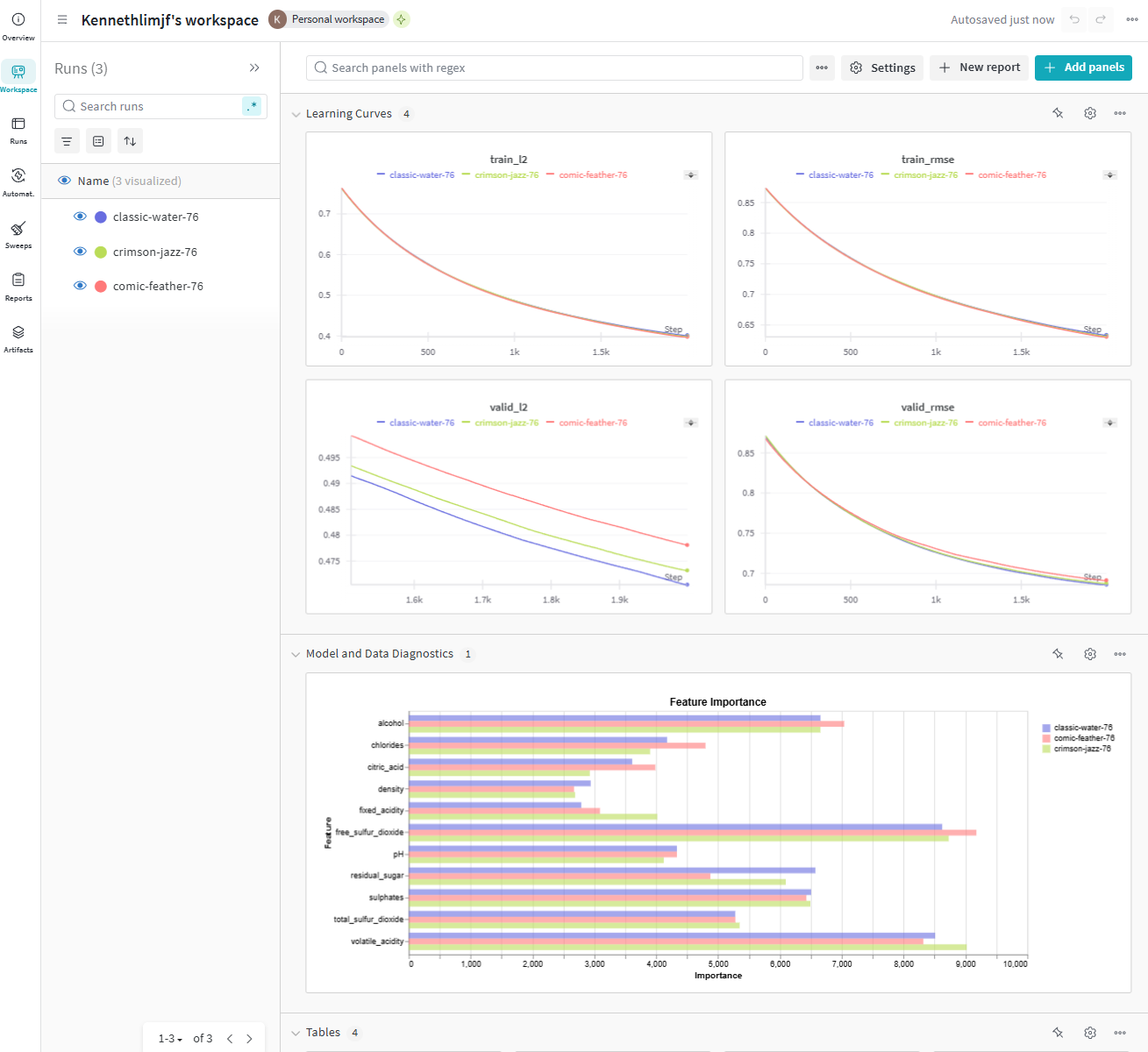
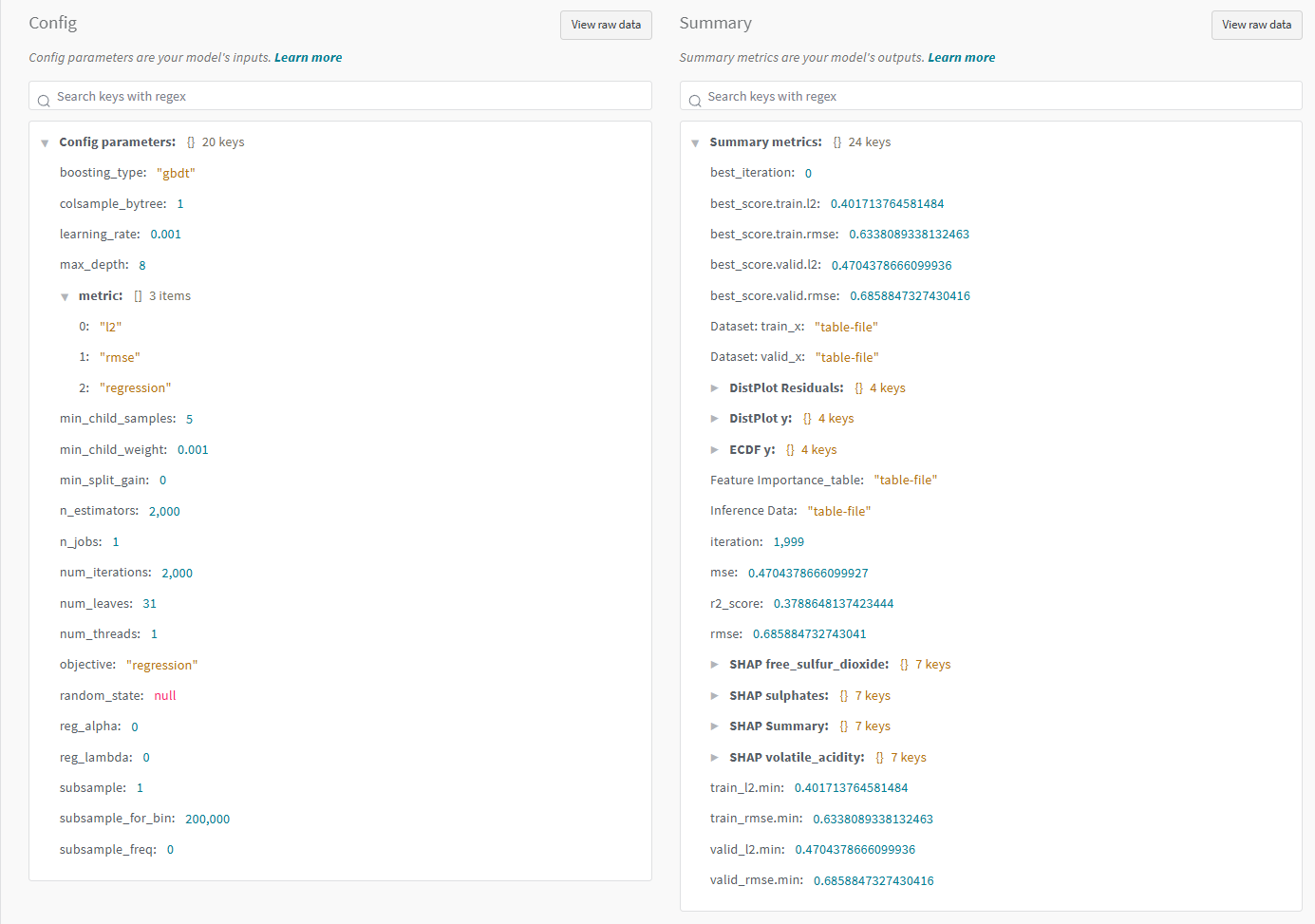
We can drill down into a single experiment/run to view more details. So clicking on one of the runs, the "Overview" tab displays all the hyperparameters used for the run and its summary results:
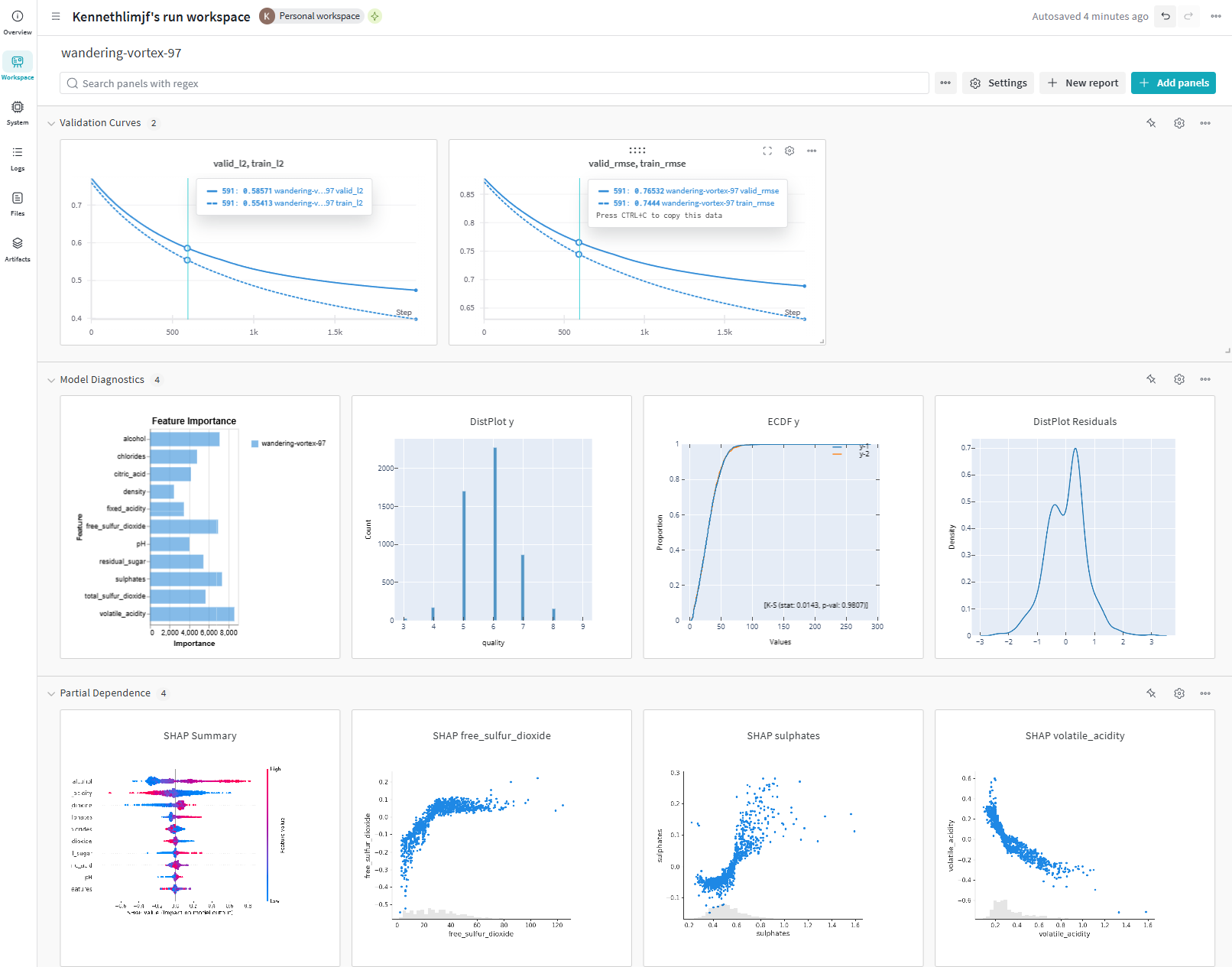
The "Workspace" tab for a run is similar to the Project level, except that now it displays all the information that we have logged for this particular run:
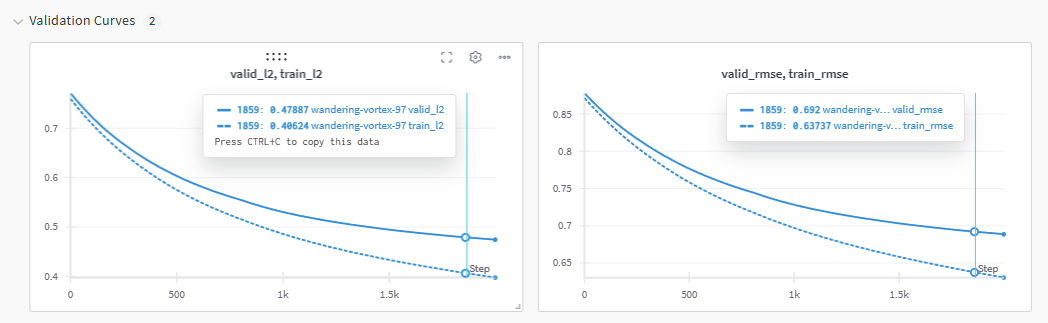
When you call wandb.log({"chart_name": plt}), WandB automatically converts it into a Plotly plot and displays on your dashboard. This allows you to interact and drill down closer to different areas of the chart if needed. The chart below shows the validation curve for training set and validation set, and the shape of the curves indicate underfitting. So more room to improve this model :)
Other interactive plots from Plot.ly are available in this run as well below, mainly to evaluate more in details of the model. We can easily tell the most important feature is "free_sulfur_dioxide". The target label mainly ranges from 3 to 9. The split on the target distribution does not result in significantly different distributions (p-val >> 0.05), in fact it is very similar. In terms of residual errors, we have around a error in quality score, and it's normally distributed.
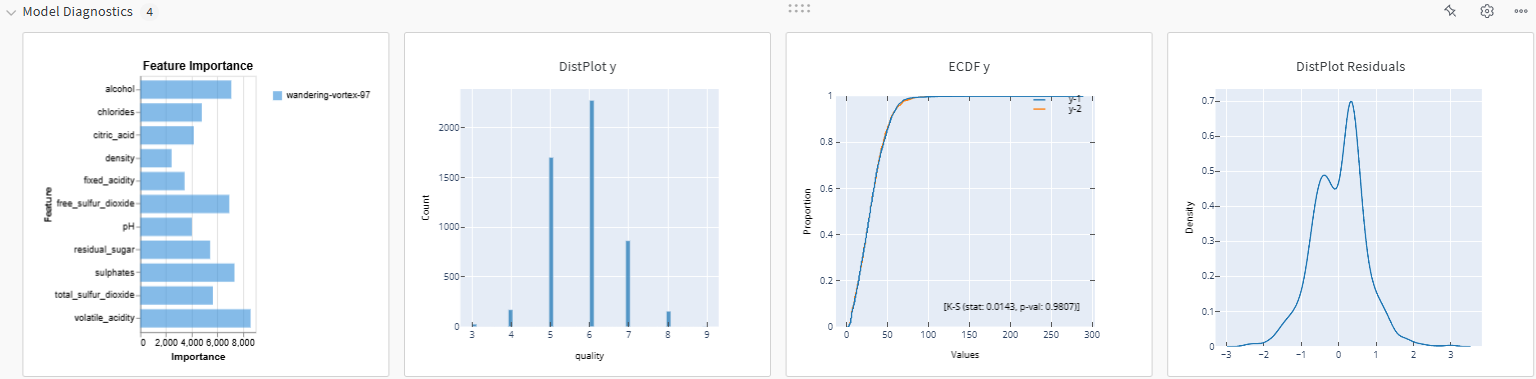
WandB also allows you to save matplotlib figures as image if you want to by passing the figure to wandb.Image and then logging it. The SHAP plots are saved as images. In my opinion, the rendering of the images on the dashboard is poor, pixelated and unclear. You'll need to click into the image to view the orignal resolution to see it clearly. Thus, perhaps saving in Plot.ly may be better if you can.
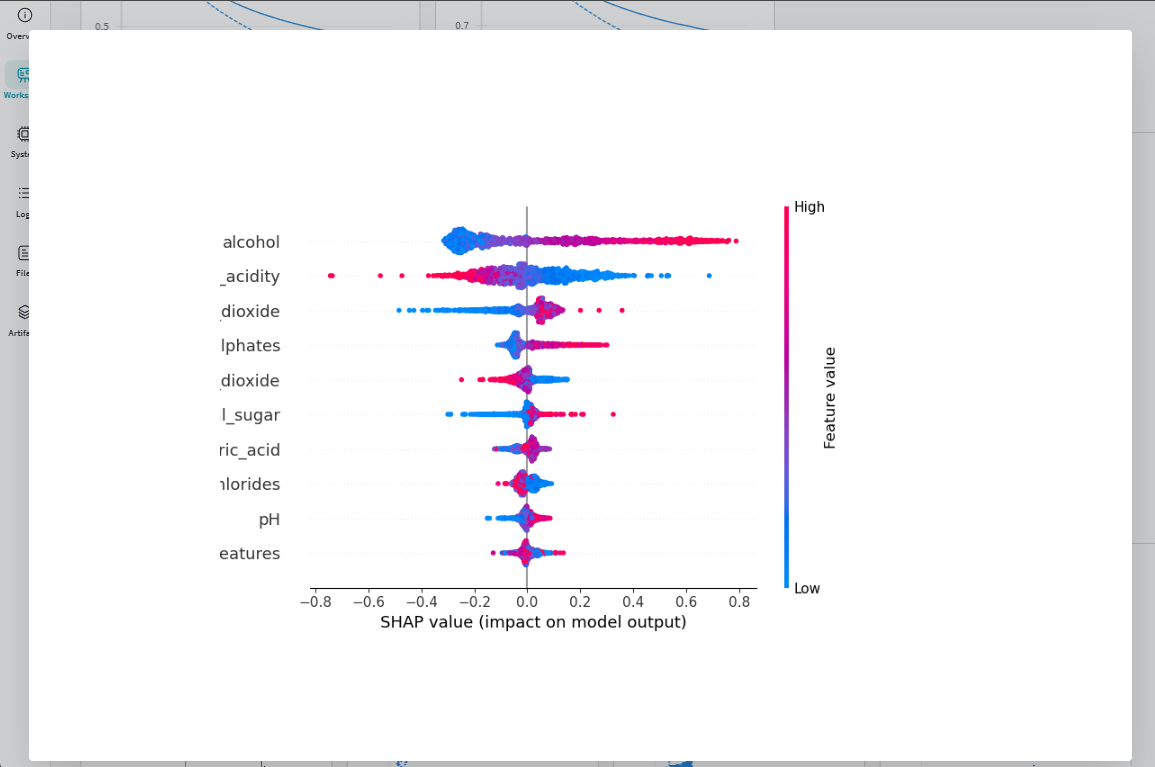
SHAP yields a very different result from the feature importance plot previously. I would say the insights from SHAP are more reliable as it: (1) has theoretical grounds from Shapley values to ensure fairness among feature attributions, (2) provides local explanations that rolls up to global level, (3) handles feature interactions and correlations (In calculating feature importance by gain in tree models, if two features are highly correlated, the one with higher information gain gets all the credit). If you're interested in learning more about more SHAP works, Molnar (2022) did a very fantastic job to explain it here: Interpretable Machine Learning: A Guide for Making Black Box Models Explainable
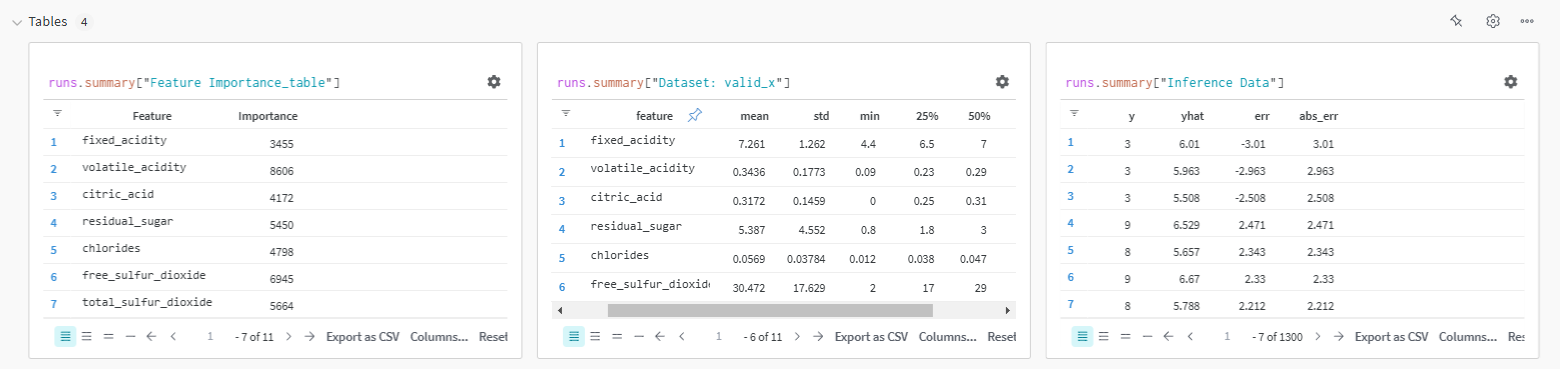
Data tables are can also be viewed in the dashboard, and can be downloaded as CSV directly, which is very convenient. The data tables show summmary statistics of train and validatiion datasets where you can briefly compare the two distributions to ensure they're balanced. Other data like inference data is also available to view the predictions.
WandB also automatically logs a range of system metrics out of the box to help monitor and optimize your machine learning workflows. These include CPU and GPU utilization, RAM usage, disk I/O, and network activity during training. This can be especially useful in distributed and/or heavy and long running deep learning loads where potential bottlenecks, hardware utilization, and performance issues are often critical to achieving efficient scaling, minimizing training time, and maximizing resource usage.
4. Summary
Experiment tracking and versioning are essential components of any robust machine learning pipeline, providing clarity, reproducibility, and actionable insights.
Using WandB, I have designed and implemented a simple experiment tracking pipeline with the ability to version and record all my future runs. I have also demonstrated how easy it is to analyze and compare across different models on the platform. Basically, all we did is just logging, and we can have charts ready for comparison or analysis. For any serious ML project, investing a day to set this up once, is just so valuable.
Personally, I felt the dashboard visualization tools and the interactive graphs that can be connected to other graphs within a panel, made the job of analysis/comparison much easier. And that is a unique strength of WandB as a experiment tracking platform.
I hope this has been another useful post to you, and you have a great day! Thanks!
References: