- Published on
Quick and Effective Testing of dbt Data Pipelines
- Authors

- Name
- Kenneth Lim
Data Build Tool (dbt) is a powerful open-source framework for managing data transformations. dbt and Apache Spark or other data warehouses such as Google BigQuery or RedShift are common data stack that many tech companies use to build production-grade data pipelines.
In this post, I will be using mainly dbt-utils and dbt-expectations to test a data pipeline using a test-driven approach. To work on something lightweight and quick, the DBT has already a sample project which can get you up and running in no time. It uses DuckDB as database and contains simple sample dataset to already work on. So let's start.
1. Getting Started
We want to get started ultra fast. So get and install UV, an extremely fast Python package and project manager, written in Rust.
curl -LsSf https://astral.sh/uv/install.sh | sh
Restart your shell and check the version to see if it has installed correctly:
uv --version
Now let's get started with setting up project quickly:
git clone https://github.com/dbt-labs/jaffle_shop_duckdb.git &&\
cd jaffle_shop_duckdb &&\
uv init --python 3.12 &&\
rm -f hello.py &&\
uv venv &&\
uv pip install -r requirements-dev.txt &&\
uv pip install -r requirements.in &&\
source .venv/bin/activate && dbt seed
The above command clones the DBT sample repo, sets up virtual environment with Python 3.12, and installs the required python packages. By running dbt seed, our database will be populated with raw_customers, raw_orders and raw_payments. All that done in less than a minute :)
It's recommended to use VSCode for this project since quite a few features has already been set up by the DBT team. At the project root, start VS Code: code .. This will trigger dbt build when VS Code starts up and you should see it running successfully.
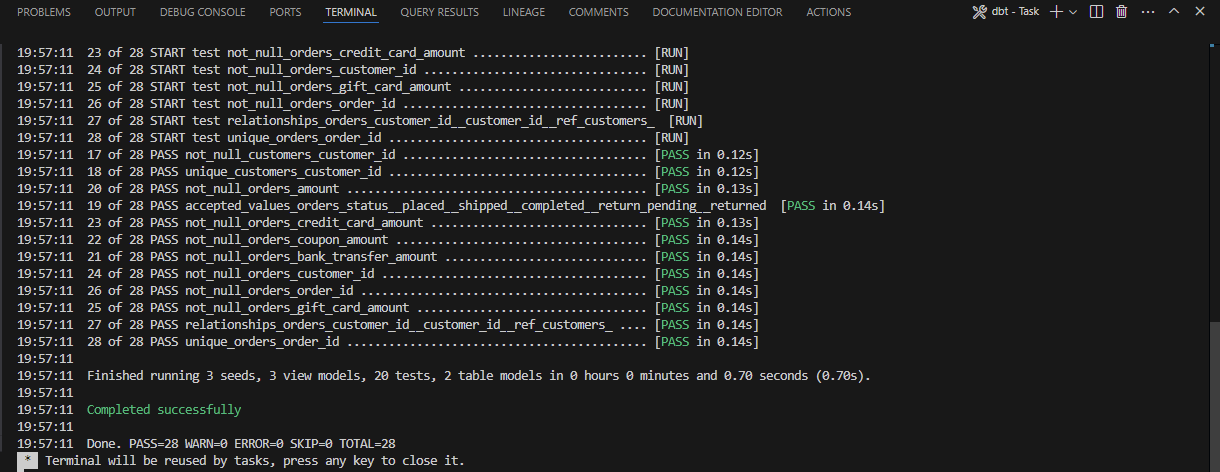
You can also install the recommended vs-code extenstions by going to the Extensions tabs and search "@recommended".
Create a dbt packages file packages.yml in the project root and install the dbt dependencies via shell bash:
packages:
- package: dbt-labs/dbt_utils
version: 1.3.0
- package: calogica/dbt_expectations
version: 0.10.4
dbt deps
We're all set now we can start implementing our tests.
2. Test-Driven Approach to Building Data Pipelines
Test-Driven Development (TDD) is a software development approach where tests are written before the code, ensuring that functionality is implemented only to meet test requirements. This process improves code quality, promotes modular design, and helps catch bugs early. TDD also provides a safety net for future changes, making code easier to maintain and refactor while fostering developer confidence.
TDD can be applied to building data pipelines by defining tests for data quality, transformations, and outputs before implementing your SQL pipeline logic. For example, you can write tests to validate schema conformity, ensure required fields are not null, or verify that transformations produce expected results. Then, build and refine the pipeline to pass these tests.
With dbt-utils and dbt-expectations, we can quickly define our tests with minimal effort and yield the benefits of testing.
To demonstrate TDD here, we will have some new requirements for the customers table (Requirements are examples for demonstration and may not make sense in reality):
Data Requirements:
Customer ID
- Needs to be unique and present
- Needs to match with our source
Customer Name
- Every customer has a first name and last name
- The last name value should be censored to comply with a random PII Data Compliance Law
- No two customers have the same name.
first_name,last_nametogether should be unique.
Order Dates
- Record the first order date and most recent order date
- First order date must be less than or equal to most recent date
Number of Orders / Total Order Amount / Average Order Amount
- Needs to be calculated for each customer
- If a customer has zero value for any of these, it should show zero
- Dollar amount needs to be accurate to the dollars and cents
- Dollar amount can record up to a trillion dollars
Tip: The idea is not to be overly exhaustive on tests/requirements but to cover critical cases in order for business applications to work. Being overly exhaustive without being critical, results in needlessly breaking pipelines over non-critical issues, and spending resources for no good reason.
With the requirements set, lets modify models/schema.yml and add our new tests
version: 2
models:
- name: customers
description: This table has basic information about a customer, as well as some derived facts based on a customer's orders
tests:
- dbt_utils.unique_combination_of_columns:
combination_of_columns:
- customer_id
- first_name
- last_name
- dbt_expectations.expect_column_pair_values_A_to_be_greater_than_B:
column_A: most_recent_order
column_B: first_order
or_equal: True
columns:
- name: customer_id
description: This is a unique identifier for a customer
tests:
- dbt_expectations.expect_column_to_exist
- unique
- not_null
- dbt_utils.cardinality_equality:
field: customer_id
to: ref("stg_customers")
- name: first_name
description: Customer's first name. PII.
tests:
- dbt_expectations.expect_column_to_exist
- not_null
- name: last_name
description: Customer's last name. PII.
tests:
- dbt_expectations.expect_column_to_exist
- not_null
- dbt_expectations.expect_column_values_to_match_regex:
regex: "^[A-Z]{1}\\.$"
- name: first_order
description: Date (UTC) of a customer's first order
tests:
- dbt_expectations.expect_column_to_exist
- name: most_recent_order
description: Date (UTC) of a customer's most recent order
tests:
- dbt_expectations.expect_column_to_exist
- name: number_of_orders
description: Count of the number of orders a customer has placed
tests:
- dbt_expectations.expect_column_to_exist
- not_null
- dbt_utils.accepted_range:
min_value: 0
max_value: "number_of_orders"
- name: total_order_amount
description: Total value (AUD) of a customer's orders
tests:
- dbt_expectations.expect_column_to_exist
- dbt_expectations.expect_column_values_to_be_of_type:
column_type: "DECIMAL(16,2)"
- not_null
- name: average_order_amount
description: Average value (AUD) of a customer's orders
tests:
- dbt_expectations.expect_column_to_exist
- dbt_expectations.expect_column_values_to_be_of_type:
column_type: "DECIMAL(16,2)"
- not_null
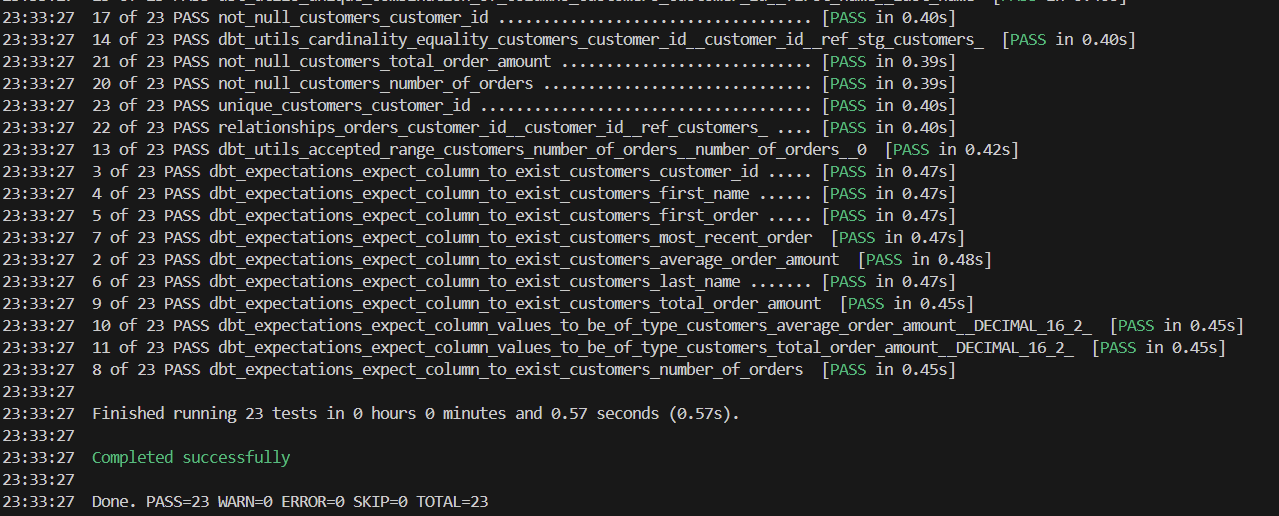
dbt run --select customers && dbt test --select customers

If we run the above, we should see some tests have failed. Seeing failure is good. This means we can start implementing the logic to fulfill the requirements. Each time you implement a change to fulfill a requirement, you can simply re-run the pipeline and test the outputs. This is done iteratively until you pass all tests.
This is the completed implementation passing all tests:
with
customers as (select * from {{ ref("stg_customers") }}),
orders as (select * from {{ ref("stg_orders") }}),
payments as (select * from {{ ref("stg_payments") }}),
customer_orders as (
select
customer_id,
min(order_date) as first_order,
max(order_date) as most_recent_order,
count(order_id) as number_of_orders
from orders
group by customer_id
),
customer_payments as (
select orders.customer_id, sum(amount) as total_amount
from payments
left join orders on payments.order_id = orders.order_id
group by orders.customer_id
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order,
customer_orders.most_recent_order,
customer_orders.number_of_orders as number_of_orders,
customer_payments.total_amount as total_order_amount
from customers
left join customer_orders on customers.customer_id = customer_orders.customer_id
left join
customer_payments on customers.customer_id = customer_payments.customer_id
)
select
customer_id,
first_name,
last_name,
first_order,
most_recent_order,
coalesce(number_of_orders, 0) as number_of_orders,
cast(coalesce(total_order_amount, 0) as decimal(16, 2)) as total_order_amount,
cast(
coalesce(
{{
dbt_utils.safe_divide(
"coalesce(number_of_orders, 0)", "coalesce(total_order_amount, 0)"
)
}},
0
) as decimal(16, 2)
) as average_order_amount
from final
3. Summary
In summary, we have:
- Installed and setup a sample dbt project in ultra-fast fashion
- Implemented tests using
dbt-utilsanddbt-expectations - Implemented changes to a dbt model pipeline based on requirements in TDD fashion
Testing data pipelines ensures the accuracy, reliability, and quality of your data, reducing the risk of errors propagating through downstream processes.
In this post, although I have only demonstrated testing a single table, dbt allows testing end-to-end in the entire DAG pipeline. This enables teams to make changes confidently and perform end-to-end regression tests without worrying something downstream will break when deployed to production. This approach fosters a more resilient data infrastructure.
Thanks for reading, and hope you have a great day ahead!